
这是我记录研究进展与思考轨迹的地方,若你对这一领域感兴趣,不妨读一读。
2026年01月
2026/01/30 周五
这一周分成了两大部分:无穷无尽的修正论文中的日语表达;检查为什么AIM-PLUM不能很好的反应AIM-ALPHA的结果(理论上来说比如说AIM-ALPHA计算美国的2100年耕作地面积为1000kha,那么在AIM-PLUM的下推中,把数据分布到格点中时,美国的所有格点值加一起一定等于1000kha,也就是数据是饱和且对应的)
关于修正论文表达: 这里我是真的要感谢我的学长,不厌其烦的一遍一遍帮我修正各种地方。这里不说名字,但是我是真心的感谢🙏🙏🙏。 经历了修改后,我意识到了两件事:1.我的日语写作是真的差;2.上课学的日语和学术日语是截然不同的。
希望修士的时候能有所改进。
而第二部分:
- 不管的region mode 还是 basin mode,AIM-PLUM的推计结果都是和AIM-ALPHA的结果不一致的。
- 这里的不一致是 PLUM的话推计结果一定比ALPHA小,但是正常应该是相等的。
- 作为原因有以下可能:
- 各个计算没有成功满足制约条件
- 如果满足了的话,模型输入的某一个parameter可能有bug
- 模型本身就是有问题的
这部分的话我估计大概率是得在离开研究室之前完成的。
2026/01/24 周六
这两周里主要干的事情有:
写完了GTAP的论文并修改上交
准备了全体组会的发表资料,并相应做了一部分数据的修改和计算
进行了组会的发表,这次发表是毕业答辩的排练
和教授汇报了关于AIM-PLUM的问题,并和两位学长+教授一起进行了长达两个小时的探讨
编写了毕业论文的摘要并修改
简单修改了毕业论文的前三章节:背景、既往研究 手法
未来一周要干的事情:
补全毕业论文的结果和考察部分
细致修改毕业论文的全部内容
到现在为止研究的目的就比较明确了,第一点是【输入分辨率高会使土地利用下推结果更准确】,第二点是【输入分辨率高可以让下游的下推模型更好的传达上游模型的信息至格点数据】。
不过在发表后教授提出了两点问题:
- 利用基准年2005年的数据来比较是否逻辑上可行,因为模型本身就是基于2005年的数据来进行推算的。如果可行的话,把单一的和2005年的数据比较换成和2050-2005的差值比较——也就是比较变化趋势可能逻辑上会更通顺一些。
- 在basin mode中,正常状态下经过AIM-PLUM下推后各流域数据应该和下推前保持完全一致。但是我的结果显示虽然整体上是线性一致的,但是并不是完全相同。所以教授觉得可能是模型出了一些问题。
发表后和教授探讨了一下AIM-PLUM的格点计算问题。洋洋洒洒讨论了前三十分钟后,发现教授印象中的和实际的数据完全不一样,给我的信息也是错的。
后面进入探讨接下来怎么做的环节。改了一下我的分析方法。我已经做完了分析得到了数据,但是这个的优先度要放在毕业论文后面了。(和教授说明了一下情况,教授允许我不大改目前的论文,这部分分析就是做着但是不用加入论文。万幸了)
2025/01/07 周三
2025/12/27-2026/01/04是日本的新年假期,因为研究已经完成了绝大部分,时间以及比较宽裕,所以这段时间基本就纯玩了(就是没学习)。
从01/05开始按照新的研究计划一步一步进行:
- 更改最终报告(已完成)
- 写GTAP英文论文的abstract
- 进行追加项目的分析:
- 确认数据分布的变化速度:变化量集中程度等
- 对变化量去做 Moran’s I
- 对数据计算尖度(Kurtosis)
2025年12月
2025/12/26 周五
居然有一个月都没有记录研究进展了,今天给补齐。这一个月发生了很多事情,计划变化了很多,产出也有很多。我按时间一点一点来。
···
2025/12/08-2025/12/16 最终报告执笔
论文的最终目的是
- 判断region 和 basin 模式下土地利用的推计哪一个在基准年更准确。
- 判断在基准年以后的两个模式的分布模式:分布差别,数据集中程度,等等。
所以基于以上目的做了如下分析
- 计算各年份的两个模式的输出差值的四分位数以此判断差值的分布情况
- 计算了在基准年下两个模式和LUH3的Kappa系数
- 计算了耕作地、牧草地、森林各自的变化最大的流域并作图
- 从流域分辨率聚合地域分辨率,计算两个模式的收量
- 计算了两个模式对于基准年的Kappa系数的变化(2010 vs 2005; 2020 vs 2005)
- 计算了两个模式之间的Kappa系数(判断两个模式间的输出差异)
- 计算了两个模式以及三个土地利用分类下的Global Moran’s I的值(全世界+各地域)
- 利用PREDICTS模型计算了两个模式下的生物多样性指标BII的值
并总结成了论文。第一稿的话算上参考文献一共50页,20000+字。上述计算大多使用python的numpy、pandas和matplotlib库。为了计算一些特定系数(比如Kappa)和更改文件格式也用了一些特殊的库。
在这途中有一些感悟:
- 对于数据分析来说numpy和pandas真的是重中之重。
- 不管对于什么而言,只要是科研,画图就是必须要掌握的。
- 把功能用函数封装,目前来讲还用不到类
- 每写完一个函数都要调试,所以用ipynb >>> py 文件
- 多用版本控制git
- 文件夹的分类一定要细分,否则一堆文件在一个文件夹里分不清哪个是哪个的。
···
2025/12/16-2025/12/22 最终报告发表准备
这段时间就是把论文准备成PPT。没什么太多可说的。
有几点有些许变化:
- 并不是收量变化会导致分布会变的分散或者集中。整体的机制是这样的:AgLU模型会考虑各个国家和流域的需要、生产力、出口进口贸易等等来确认该国家、地域的农作物产出面积。随后AgLU模型会输出400个地域的粮食生产面积,能力等,我们把这个数据输入到AIM-PLUM里,AIM-PLUM会去在考虑费用等情况下去吧耕作地面积给分配到各个各自里。所以说收量增长和土地利用面积增加会有相关关系但不是因果关系。
- 从上面的解释就能看出来两个模式的区别,在basin模式中,因为输入数据完整的保留了各个流域的计算结果,所以下推后的地图包含了很多情报和细节。在region模式中,因为吧数据直接聚集到了大洲分辨率,所以所有情报就被消除掉了。
- 结合1,2,进行了一个新的计算,就是对于特定的一年,把每一个地域的basin模式、region模式、AgLU的农作物输出面积做成两个散点图。(basin,Aglu)和(region,AgLU),实际结果来看,basin,AgLU的结果线性相关更大一些——basin模型会更加随着上游模型的输出变化而变化。
···
2025/12/23-2025/12/26 最终报告反馈及题目决定
从反馈来看,研究整体已经满足了毕业论文的要求。但是很令我无语的一点是,在反馈和comment的环节,老师说:“你现在的指标不能反应我想看的东西。”意思就是说,其实我想看的是另外一个事情,你做的东西看不出来。后来经我了解,本来aimhub的17地域下推结果存在一个问题就是,经过线性规划之后,模型输出在有的地方会突然蹦到最大值然后锁死——这明显不符合规律因为作物面积的增长都是随时间线性增加的,不会出现突然一大片从无到有的情况。所以开发了用AgLU的Basin和Region模式,目的是通过使输入变得更加精细,避免上述问题。
然而老师再给我传达研究目的的时候简单的把这个问题称为了:“我们想看哪个模式更好。” 能排除我最开始没听清楚的可能,因为我问了所有学长,所有人都表示他们也不清楚,不过他们也习惯了:「この研究室はそんなもんだ」。这么说的话我就释然了,不过依旧不能苟同这种做事方法。
为了进一步的展现模型的问题到底有没有解决,准备做以下新的指标:
- 不直接对数据做Moran’s I,对每相邻两年的差值做Moran’s I,这样应该能反映出变化是逐渐,均匀的还是突然、激烈的。
- 对数据做尖度的计算,判断数据是否存在剑锋(就是突然增加)
- 以及对于差值计算 比如说 最大的百分之五的格子的面积增加占了全体的百分之多少这样,来判断是不是增加全都被分配给了少数格子。
然后还有一件事:正常来说我的研究是要去参加明年六月份在京都召开的GTAP会议的发表的。但是因为我明年不在研究室了,所以老师想让学长拿我的结果去发表(一作还是我的名字)。为了参加这个会议,我需要在一月份先交一个3页的英文abstract,如果合格了的话就在四月前再交一个完全版。
我目前有点犹豫,在犹豫收货和付出是否成正比,因为写论文需要花时间,但是就算去发表了我也收获不到什么,因为可能不会读博。唉,再考虑考虑。
···
2025年11月
2025/11/27 周四
周二一直都在尝试debug 流域和格点的mapping程序。
但是遇到了很多问题:
- 程序的依赖packages在hpc上很难实装,而在本地电脑上因为计算量太大而不现实。
- 程序的输出需要调用gams的api接口来输出gdxfiles 但是貌似我的gams版本不够没法调用(最新的因为要花钱不能装)
- 因为没有办法运行所以也不知道怎么debug,单看代码又太抽象
尝试解决:
- 配置一个conda环境,在里面安装所有依赖
- 第二个问题至今没有解决——学长和我说这种debug本来不应该是B4的学生做的,但是没办法老师就让了。 他说最好的方法就是先放置一下,不管他。
周三进行了发表,发表整体还是比较顺利,但是在答疑的过程中对自己表现不是很满意,学姐用英文问我然后我也是好久没练了,也有点紧张,回答的没有什么逻辑。还是得多练练口语才行。
发表结束后就正式的进入考察分析环节,接下来就是对数据进行各种计算了。最终报告的deadline是12.16,希望在这之前能顺利的写完。
2025/11/23 周日
才有时间更新一下周五的结果
老师貌似对于我的成果还是比较满意的,整体的组会下来整理几点:
- 需要再去看一下mapping的程序,看看对于格子的分配有没有遗漏或者重叠。
- 对于结果的考察增加以下内容:1、利用kappa系数观察不同地图的相似度。2、计算对于基准年的各年份的土地利用变化。3、继续修改predicts直到出结果。
下周全体发表,发表完之后进入接下来的结果分析环节。
2025/11/21 周五
今天是sustainability的组会,趁着孔隙写一下总结。
周一成功的跑出了结果,在master branch下region mode 和basin mode输出了看起来正确的数值。
周二:为了验证数值的准确性,把400流域下的数值进行了聚类——合并成了17地域的类型。和region mode进行了比较后发现几乎在所有项目两者都有近10%的误差于是开始请教学长、查代码、问老师等等等。
周三大组会,开完之后问了老师如何判断,小老板说了一大堆,我挑重点的回去试了试,但是也没太整明白。只查到了在data prep下有一些格子看起来有一些奇怪。等待今天组会问老师。
周五小组组会,目前还没到我,我问完老师后更新。
2025/11/17 周一
今天又是收获满满的一天。
到达研究室开始一直在debug:master branch 的 basin mode 的输出非常奇怪,所以一步步溯源往回找各个值是怎么算出来的。
其实这是一个非常痛苦的过程,因为对于刚进研究室没怎么用过模型的人来说,是这样的:
- Z的数值有问题,需要看Z的数值是怎么计算来的
- Z由X+Y组成,看X+Y是怎么来的
- X由U+V+W组成,还分情况讨论
- Y由U+T+S组成,也分情况
- 然后无限套娃
重点是每一个变量的名字比我的例子里的复杂多了,比如
1 | Y_pre("OL",G)$(landshare(G))=Y_pre("OL",G)*landshare(G)+(1-landshare(G)); |
寻找了一大通之后发现进入了纯nlp环节,代码不是我能看得懂的,遂打算求助于老师。这时候发现,
现在在重新跑模型尝试。
2025/11/10 周一
今天干的事情有亿点点多:
小老板说模型做完了,于是我就试着跑了一下
master branch的region mode和basin mode。上来直接是一个大失败
D1/D20 ,仔细看了一会log之后发现是模型在映射scenario(情景)名字的时候,错误映射了一个已经被淘汰的情景名称。修改了这个问题之后分开来讲
- basin mode: base year 和 future year 的simulation 都生成了,现在卡在scenario merge这一块,也就是把输出给合并起来的这一部分。截至写文时还在跑。
- region mode: 所有地域的base year simulation全部失败。输出:
Model has been proven infeasible。看了看原因发现是Reduced gradient less than tolerance,也就是梯度下降小于阈值(用人话说是计算不收敛,无效)。
给老板们发了slack说明问题,目前还在等回复。
看起来事情不多但是寻找哪里出现了问题占用了相当长的时间。精疲力尽。
2025/11/05 周三
几乎毫无进展的一周:小老板还没有联系我她做没做完模型,她不进展我就没法继续。今天给她发了邮件询问,希望能有结果。
非要说干了什么的话,用develop_basin_mode跑通了predict,输出了生物多样性指标(BII)。不过貌似有点bug:有一些地域的值异常的高或者低,能到达10的30次方左右笑(BII应该在0-1之间)。
2025年10月
2025/10/30 周四
周一跑的两个模型都没有跑通,于是准备用之前的develop_basin_mode分支来跑AgLU/AIM-PLUM的basinmode + predict。
但是之前merge了老师上传的PR之后 这个分支就充斥着bug,根本无法运行。于是只能一遍一遍退回commit来找到一个可以运行的版本。
回退了两次之后终于找到了一个似乎能用的,截止写文模型还在运行。
(晚上八点多模型终于跑完了,这次比上次还多用了2个小时,模型模拟的时间已经来到了8小时)
2025/10/27 周一
今天主要内容就是和学长确认了一下整个模型的进度以及接下来的やること。
用master分支跑一下AgLU/AIM-PLUM的basinmode + predict
用master分支测试一下AgLU/AIM-PLUM的regionmode
截止本文时间,模型已经跑完了但是结果确认需要等到周三去研究室才能进行
2025/10/20 周一
本来以为上周进展挺顺利,这周任务应该不重。但是今天又和老师来回mail了无数轮来确认模型运转时间长的原因,导致也没能早回家。
和老师交流后目前确认到的内容如下:
- 之前downscale AIMHUB的时候,模型输出的是17地域数据,也就是把世界分成17份。downscale一共用时90分钟。现在AgLU模型把全世界分成400份(虽然不均匀)但是其中有一些区域的用时反而比之前多了。也就是说模型下推小的面积比大的面积用时还要长。老师怀疑模型根本没有输出确定解但是没有证据。
- 模型一共用32个CPU线程;整个模型里一共400个流域,每一个流域要按时间计算10次(2010,2020,…,2100),所以一共是4000次计算。这四千个计算是随机分配到32个CPU线程里的!(当然对于每一个流域而言,靠后的年份肯定是在所有的前置年份计算完成后再计算的(因为后面的需要前面的数据))我之前以为是把400个流域随机分给32个线程,没想到是完全随机分的。
- 两个很有经验的学长以及老师们对原因毫无头绪😅
接下来是等待小老板把需要改动的regionmode做完。
2025/10/17 周五
今天小老板给了我新版的AgLU模型,好像解决了昨天说的问题。截止写文模型还在跑。
AgLU400流域的下推至此就小告一段落,接下来的是把400流域的数据重置为17地域的数据并让AIM-PLUM跑通,这涉及如下几个小问题:
- 如何把数据从细分的400地域映射到17地域
- 如何让AIM-PLUM识别这些数据
- 更改AIM-PLUM的数据输入部分使其能直接对应AgLU的最新标准输出
接下来就是一点一点做了。
2025/10/16 周四
模型运行结束了,虽然中间过程数据已生成,但最终的 nc 文件未出现预期更新,还是之前的零星几个国家的程度。
于是开始从头看代码,运行文件,报错文件。最后定位到 base year simulation那里,有20个流域(多为热带岛国,可能由于这些流域在地理或数据特征上的共性所致)在进行基准年计算的时候显示
Equation infeasible due to rhs value (约束条件右端值设置不当导致方程不可行)
所以导致该流域的base.gdx, 2005.gdx无法生成。后续也就无法继续根据基准年数据来模拟未来的结果(2010…2100.gdx)。因为没有后续数据,所以在整合gdx的时候,形成了一个空文件,导致在进行计算的时候报错,无法形成base_SSP2_BaU_NoCC.gdx导致后续所有都生成失败。
作为解决方法,我在第一次生成数据之后手动修改Plum_exe.sh;执行脚本文件,阻止其粘贴空文件到下一个执行文件夹。这样的话虽然少了20个流域,但是模型可以执行到最后并输出数据。后续计划加入在执行脚本中添加条件判断,避免空文件被复制至下一阶段目录。
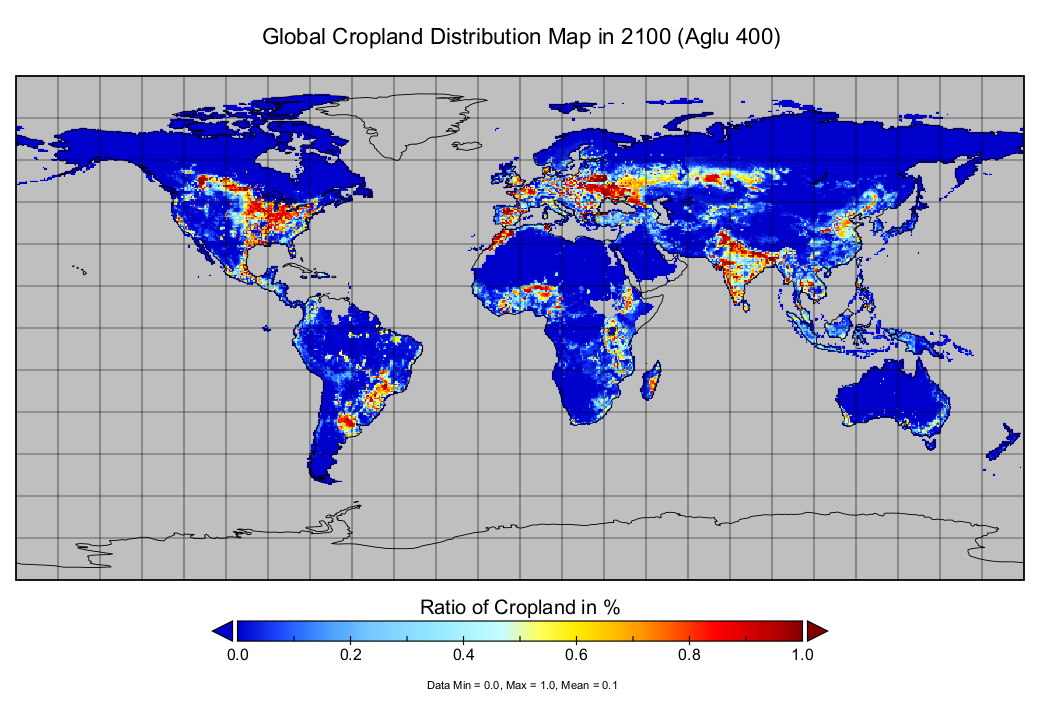
下面这张图是本次进展的结果之一:这张是模型预测的2100年全球农作物分布图。图片下方的scale的caption有一个小错误——并不是%百分率而是占比,也就是说深红的那个格子百分之百都是农作物,而深蓝格子没有农作物出现。
2025/10/15 周三
写模型的老师告诉了我把 AIMPLUM的Aglu版 的设定更改为 global: on之后应该对应修改Plum.sh 。至此,困扰了我和前辈一个月的模型bug终于被解决了。其实这不是bug,而是沟通问题,如果老师能在递交模型的时候告诉我们参数设定对应的改动,就不会有后续的麻烦了(因为模型本身并没有readme或者说明doc)。
截止写总结,模型已经运行了3.5小时了,仍然没有结束。对于俄罗斯和加拿大的每个流域,每计算10年大概需要花40分钟,所以从2005年计算到2100就大致需要6个小时。大概是对比其他国家而言,上述的流域本身的面积非常大。