
本文章是为B站简博士统计学习所做的笔记
【合集】十分钟 机器学习 系列视频 《统计学习方法》——监督学习篇 by 简博士
(由于我看完了前三个视频才想起来要做笔记,所以笔记从1.4开始)
1.统计学习概论
1.4 模型评估与模型选择
1.4.1 训练误差和测试误差
- 训练误差是在学习系统上,对训练集的模型结果和实际结果的误差。
- 测试误差是在已经完成学习的系统上,对测试集的模型结果和实际结果的误差。
1.4.2 误差率和准确率
- 示性函数是用 0 和 1 来表示“属于某集合”这个条件是否成立的函数。
- 误差率:预测值和真实值不相等的样本点的个数占测试集里样本总个数的比例
- 准确率:预测值和真实值相等的样本点的个数占测试集里样本总个数的比例
- 误差率 + 准确率 = 1
1.4.3 过拟合
- 龙格现象:龙格现象是高次多项式插值在等距节点上出现的端点振荡。节点越多越糟,插值曲线在两端会大幅偏离原函数。
- 过拟合:学习所得模型包含参数过多,出现对已知数据预测很好,但对未知数据预测很差的现象
1.5 正则化和交叉验证
1.5.1 正则化
- 实现结构风险的最小化策略
- L1 正则(L1 norm):在损失函数里,加上 “所有权重的绝对值之和”。
- L2 正则(L2 norm):在损失函数里,加上 “所有权重平方的和”。
- L1 正则让权重稀疏(变 0),L2 正则让权重变小(但不为 0)——两者都是为了防止过拟合。
- 奥卡姆剃刀原理:在模型选择时,选择所有可能模型中,能很好解释已知数据并且十分简单的模型
1.5.2 交叉验证
- 数据充足的情况下:分成训练集,验证集,测试集
- 不充足:
- 简单交叉验证:训练集,测试集
- S折交叉验证:随即将数据分成S个互不相交大小相等的子集,S-1个座位训练集,余下的为测试集

S折交叉验证
1.6 泛化能力
1.6.1 泛化误差 和 泛化误差上界
- 模型在从未见过的新数据上的误差,就是泛化误差。
- 泛化误差上界:模型在未来最糟糕情况下,也不会比某个水平更差。
1.7 生成模型和判别模型
1.7.1 生成模型和判别模型
- 生成模型:先学会 X 和 Y 的联合分布 P(X, Y),再用它推导出 P(Y|X) 来做预测。例:朴素贝叶斯和隐马尔科夫模型
- 判别模型:由数据直接学习决策函数f(X)或者条件概率分布P(Y|X)作为预测模型。例:k近邻法,感知机,决策树
1.8 监督学习应用:分类问题
1.8.1 分类问题:评价指标
- 分类准确率:对于给定测试数据集,分类器正确分类的样本与总样本数之比
对于二分类问题:
| 预测/真实 | 正类 | 负类 |
|---|---|---|
| 正类 | TP(True positive) | FP |
| 负类 | FN(False negative) | TN |
评价指标:
- 精确率: $P = \frac{TP}{TP+FP}$
- 召回率: $R = \frac{TP}{TP+FN}$
- 调和值: $\frac{2}{F_{1}} = \frac{1}{P}+\frac{1}{R}$
1.8(2) 监督学习应用:回归问题和标注问题
1.8.1 回归问题
- 类型:
- 按输入变量个数:一元回归,多元回归
- 损失函数: 平方损失
2.感知机
2.1 模型介绍和学习策略
2.1.1模型介绍
- 感知机(Perceptron) 是一种最简单的线性二分类模型,也是神经网络的起点。
- 给定输入向量x 感知机计算 $y = sign(w \cdot x + b)$
- w:权重
- b:偏置
- sign():输出+1或-1
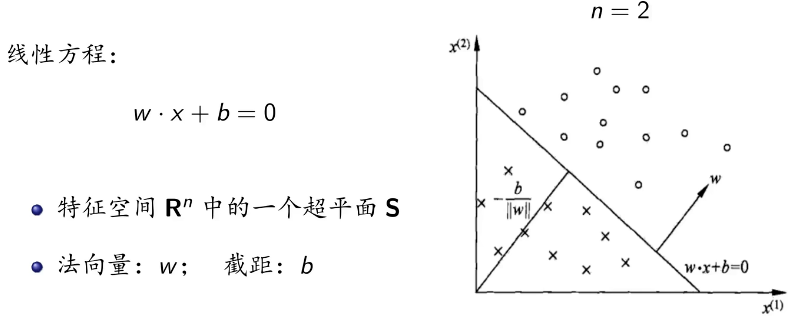
模型介绍:几何含义
2.1.2 学习策略
- 只能解决线性可分问题
- 损失函数: 感知机通过最大化误分类样本的函数间隔(使其变正),让所有样本最终被正确分类。
$$L(w,b) = - \sum_{x_{i}\in M} Y_{i}(w \cdot x_{i}+b)$$
也就是说:如果模型把某个样本分错了,就把超平面往该样本的方向稍微推一下,使它下次更容易被分对。
2.2 梯度下降法
2.2.1 概念
- 梯度:某一函数在该点处最大的方向导数,沿着该方向可取得最大的变化率
$$\lambda = \frac{\partial f(\theta)}{\partial \theta}$$ - 算法:
1 | #输入:目标函数 f(θ)、步长 η、精度 ε |
2.3 算法
2.3.1 原始形式
损失函数:
$$
L(w,b) = - \sum_{x_{i}\in M} y_{i}(w \cdot x_{i}+b)
$$
梯度:
- $ \nabla_{w}L(w,b) = - sum_{x_{i}\in M}y_{i}x_{i} $
- $ \nabla_{b}L(w,b) = - sum_{x_{i}\in M}y_{i} $
参数更新:
- 批量梯度下降法(batch gradient descent): 每次迭代是使用所有误分类点来进行参数更新
- 随机梯度下降法(stochastic gradient descent): 每次随机选出一个误分类点
- 感知机使用随机梯度下降法

感知机原始形式算法
2.3.2 对偶形式
相比于基础形式每次都要修改w,b,对偶形式则为用所有样本的加权组合表示w,不直接存w。
- $w = \sum_{i=1}^{N}a_{i}y_{i}x_{i}$
- $b = \sum_{i=1}^{N}a_{i}y_{i}$
2.3.3 感知机收敛定理
Novikoff 感知机收敛定理:只要数据线性可分,感知机算法必定在有限步内收敛
- 更新次数 $k<=(\frac{R}{r})^{2}$
- 其中 r:数据间隔(两个类别的距离,越大越容易分开)
- R:样本向量的最大长度(数据越大越难分)
3.K近邻法(KNN)
3.1概念
k近邻法
k近邻法是一种基本的回归和分类方法。
主要思想:假定给定一个训练数据集,其中实例标签已定,当输入新的实例时,可以更具最近的K个训练实例的标签,预测新实例对应的标注信息
其中: 分类问题为通过多数表决的形式;回归问题为通过均值计算的形式。
3.1.1 误差率
考虑最近邻法(k=1):1-近邻预测错误的概率,就是:
对每一个类别 $c_j$,新点真实是 $c_j$(概率 $P(a=c_j)$),但最近邻不是 $c_j$(概率 $1 - P(b=c_j)$)的概率之和。
这里最开始我没太看懂,问了一下gpt让他给我举例子:
我们做一个二分类(二类 K=2)的问题:
类别:c₁ = 猫;c₂ = 狗
现在来了一个新样本 x,它到底是猫还是狗?
对于新样本 x,我们知道:
它是猫的概率:$P(a=c₁|x)$ = 0.7;
它是狗的概率:$P(a=c₂|x)$ = 0.3
对于它的最近邻 $x_i$,我们知道:
最近邻是猫的概率:$P(b=c₁|x_i)$ = 0.4;
最近邻是狗的概率:$P(b=c₂|x_i)$ = 0.6
(现实中概率来自模型估计,这里只做举例。)
公式:
$$
Err = \sum^{2}_{j=1}P(a=c_j|x)\cdot (1-P(b=c_j|x_i))
$$
如果真实是猫但最近不是的话:0.7*0.6=0.42
如果真实是狗但最近不是的话:0.3*0.4=0.12
误差率:Err=0.42+0.12=0.54
(这个解释的我觉得非常好。)
接下来我们讨论误差率的理论上下界:
当样本无限多的时候:x的最临近点无限接近x,也就是两个点本质上相同,那么最临近的类别概率=x的真实类别概率。所以1-NN/k-NN(k->inf)的误差最终只由x自己决定。
$$
Err = 1 - \sum_j P(a=c_{j})^{2}
$$
过程省略。
用人话解释一下就是:如果样本量已经足够大的话,影响机器分类的因素只有目标本身的分类难易程度(和机器无关)(例如:目标又像猫又像狗)
这是 k-NN 的理论误差率在样本无限多时的极限(asymptotic error)。
在继续说这个之前,我们先解释一下什么是贝叶斯误差:
贝叶斯误差
贝叶斯误差是真实世界中,样本x本身就不可区分的那部分错误率,是任何分类器都无法避免的最低错误率$$P^{*}(err|x)=1-P(c^{*}|x)=1-p$$贝叶斯误差是任何分类其误差的下界,既所有分类器的误差肯定要比贝叶斯误差大。因为这是属于被预测体本身的不确定性,和模型无关1-NN 的极限误差下界(最优情况下)达到贝叶斯误差。也就是说,1-NN 不可能比 Bayes error 更好,这也是机器学习的理论极限。通过计算可发现理论预测误差上界为2*贝叶斯误差即:
$P^*<=Err_{1NN}<=2P^*$也就是说 1-NN 在最差情况下,误差最多是最优分类器的两倍,但不会更坏。
对于k-NN来说,在样本量趋向无穷大的时候,如果k随着样本量增加且满足$k→\infty and \frac{k}{N}→0$则k-NN的误差收敛到贝叶斯误差。(人话版:如果有无限多的数据,并且k随数据增长,k-NN会成为世界上最好的分类器)
3.2三要素
3.2.1模型
k近邻法(k-nearest neighbor,k-NN)不具有显性学习过程,实际上是利用训练数据集对特征向量空间进行划分,以作为分类的模型。
特征向量空间
每个样本是一个向量,这些向量有很多特征(比如一只猫有特征身长和体重等等),所有这些向量所在的空间就叫特征向量空间3.2.2距离度量
$L_p$距离:
$$
L_p(x_i,x_j)=(\sum_{I=1}^N |x_i^{(I)}-x_{j}^{(I)}|^{P})^{\frac{1}{p}}, p\geq 1
$$
注:
如果p=2的话就是我们平常熟知的欧氏距离,也就是两点间距离公式$\sqrt{(x_1-x_2)^2+(y_1-y_2)^2}$
p=1时叫做曼哈顿距离(因为走起来只能横竖走,像曼哈顿的街区一样)比如从(1,2)走到(4,6)就是(4-1)+(6-2)=7。
p=正无穷的时候叫做切比雪夫距离(Chebyshev distance):走任意方向,代价由“最大的坐标差来决定”,比如之前的那个例子的话从(1,2)走到(4,6)就是max(|x1-x2|,|y1-y2|)=4。(其实这个是国际象棋王的移动方式,上下左右斜。一步可以改变两个方向,所以距离等于最大方向差)
$L_p$距离中,P越大,越强调各个坐标差值的最大值。当P趋近于无穷时,$L_p$完全由最大差值决定
不同的距离度量,也就是不同的P,取得的最近邻点也是不同的
3.2.3 k-值的选择
- 较小的k值,学习的近似误差减少,但是估计误差增大,敏感性增强,模型复杂容易过拟合
- 较大的k值,减少学习的估计误差,但近似误差增大,而且模型简单
近似误差
模型能不能代表真实规律——模型本身有多差估计误差
数据不够多导致估计模型参数是出现的误差- 随着 k 的增大,kNN 的预测由更大范围的样本平均决定,模型对局部噪声的敏感性降低,决策边界更加平滑,可表示的函数空间受到更强约束,因此模型复杂度降低。
3.2.4 分类决策规则
- 多数表决规则:有输入实例的k个近邻训练示例中的多数类决定输入实例的类。
- 为了形式化这一规则,引入指示函数 I(⋅)。当条件成立时I(⋅)=1,否则为 0。因此,I(yi=cj) 表示第𝑖个近邻样本是否属于类别 cj。
- 误分类率:
$$
\frac{1}{k}\sum_{x_i\in N_k(x)}I(y_i \neq c_j )=1-\frac{1}{k}\sum_{x_i\in N_k(x)}I(y_i = c_j)
$$ - 最小化误分类率也就是最大化正确率等价于:
$$
arg max \sum_{x_i\in N_k(x)}I(y_i = c_j)
$$ - 上式表明,kNN 分类的最优决策等价于在近邻集合中选择样本数最多的类别,即多数表决原则。